



这篇paper关注了类脑和高性能计算领域,研究coreNeuron的目的是为了令NEURON模拟器适应不断进化的计算机架构,在保证NEURON计算精度以及兼容性的基础上,使其能够模拟的网络的计算规模以量级的概念扩大。这篇paper所阐述的coreNeuron可以说是后续协同NEURON进行高性能计算的必备工具。CoreNEURON : An Optimized Compute Engine for the NEURON Simulatorhttps://neuronsimulator.github.io/nrn/coreneuron/how-to/coreneuron.htmlGitHub - BlueBrain/CoreNeuron: Simulator optimized for large scale neural network simulations.
NEURON 模拟器在过去三年中得到发展,被神经科学家广泛用于模拟神经元网络的电活动。使用 NEURON 的大型网络模拟项目具有以数百万个核心小时单独衡量的超级计算机分配。超级计算机中心正在向下一代架构过渡,如果 NEURON 能够更好地利用这些新硬件功能,这些模拟的每个核心小时完成的工作可以提高一个数量级。为了使 NEURON 适应不断发展的计算机架构,NEURON 模拟器的计算引擎已被提取并优化为一个名为 CoreNEURON 的库。本文介绍了 CoreNEURON 的设计、实现和优化。我们描述了如何将 CoreNEURON 用作 NEURON 的库,然后比较不同网络模型在多种架构(包括 IBM BlueGene/Q、Intel Skylake、Intel MIC 和 NVIDIA GPU)上的性能。我们展示了 CoreNEURON 如何模拟现有的 NEURON 网络模型,同时保持与 NEURON 的二进制结果兼容性,内存使用量减少 4-7 倍,执行时间减少 2-7 倍。
现代神经科学研究中的模拟已成为科学方法的第三个支柱,补充了实验和理论的传统支柱。 研究大脑成分、脑组织甚至整个大脑的模型提供了整合解剖学和生理学数据的新方法,并允许深入了解跨尺度和将结构与功能联系起来的因果机制。
早期的研究涉及从通道到神经元网络的方方面面,例如神经元电生理特性和多样性,细胞代谢,细胞的生化工作,细胞内级联反应在神经调节中的作用等等。那么随着神经科学,或者说类脑模拟的发展,人们为了方便分析,创造了很多模拟器引擎,通过一些简单的方程和计算表示来模拟神经元的工作。
随着神经元网络以及神经系统模拟的发展,这些仿真引擎的算力需求和计算规模就越来越大,所以就需要性能更好的模型以及硬件出色的计算机,以下是当前的五种不同的网络模型,以及其规模和复杂性,以作为参考。

我们可以看到,最小的模型几乎也是万级别的神经元数量,十万级别隔室,百万级别的突触数量,因此,每模拟一个模型都需要巨大的算力开支。
另外,markram等人(2015)的研究发现,神经元与突触的数量越多,模型计算复杂性并不一定越好,计算是受到当前技术的限制的。在这个研究中,每个神经元平均约有20,000个微分方程来表示其电生理和连通性。那么也就是说,为了模拟31,000个神经元的微电路,每25毫秒的生物时间需要解决超过6亿个方程,而这一要求对于远远超出了任何计算机的能力。应用于类脑科学的并行计算系统的研究就迫在眉睫。
基于以上原因,在这篇文章中展示了作者团队设计的NEURON 模拟器 —— CoreNEURON的内部计算引擎,适应了新兴架构,同时保持与神经科学社区开发的现有 NEURON 模型的兼容性。本文的工作目标是:利用最大的可用超级计算机,进行神经科学探索 扩展模拟器引擎以在数百万个线程上运行。另外,文章的另一个关键的设计目标是与NEURON 相比减少内存占用,因为在大规模运行时,总内存和内存带宽是稀缺且昂贵的资源。最后,我认为也是非常重要的一点,文章为了让NEURON 社区可以轻松使用此功能,他们实现了 CoreNeuron与 NEURON模拟器的紧密集成。
简单介绍了NEURON,以及神经元传递方程,值得好好看一看。
NEURON是一个模拟平台,可以模拟神经元之间的物理传导以及信息传递。
第一部分的NEURON平台简介就不做过多介绍了,想了解使用方法详见本账号文章“NEURON教程”系列。
主要介绍一下神经元的仿真机制。我们知道单个神经元通常被视为一棵称为“Sections”(“节”)的未分支电缆树。 而每个部分都可以有自己的一组生物物理参数,独立于其他部分,并被离散化为一组相邻的隔室。 神经元的隔室模型不仅考虑了神经元之间的连通性,还考虑了每个神经元的个体形态和不均匀性。 此外,神经元的电活动使用应用于每个部分的电缆方程( cable equation )进行建模,其中表示神经元在给定空间点和时间瞬间的状态的量是膜电位。 在恒定参数和基于电导的突触建模的情况下,一段电缆方程的一般形式由下式给出:
其中:
是对电缆方程的无源分量有贡献的生物物理参数(未显示单位转换因子,但每一项的单位为
)。
是沿截面的离子通道产生的主动贡献,其电导
和静息电位
可能以非线性方式取决于代表这些通道的一组状态变量。
是来自位于
位置的突触的贡献,其电导
和静息电位
可能以非线性方式取决于一组状态变量,并以强局部化方式起作用。 单个突触的单位为
,转换为
涉及 Dirac delta 函数
,单位为
,以及直径; 即,将绝对电流转换为每单位面积的电流意味着除以突触所在的隔室区域
需要将上述公式cable equation 耦合到一组描述离子通道和突触状态演变的附加微分方程,从而产生作为最终问题的 PDE/ODE 系统。偏微分方程的空间离散化导致刚性耦合方程的树拓扑集,通过隐式积分方法最有效地求解。特别是,在算术运算的数量与具有相同节点数的非分支电缆的直接高斯消除相同的意义上,具有最小度排序的直接高斯消除在计算上是最优的(Hines & Carnevale., 1997;Hines 等., 2008)。 NEURON 中非混合时钟事件驱动算法(Hines,1993)的一般结构可以分为一组在每个积分时间步执行的操作和一个进程间尖峰交换操作,其中尖峰生成时间和标识符列表同步跨所有处理器的每个最小尖峰延迟间隔。每个集成步骤的操作是:
- 事件驱动的尖峰传递步骤:执行在给定时间步长由尖峰激活的每个突触的回调函数。
- 矩阵组装步骤:计算
和
贡献并将其包含在矩阵中。
- 矩阵解析步骤:当前步骤的膜电位通过求解线性系统获得。
- 状态变量更新步骤:求解离子通道和突触状态的演化方程以推进到当前时间步长。
- 阈值检测步骤:扫描每个神经元以查看它是否满足特定的激发条件,如果满足,则更新特定的事件列表。
尽管模拟器在 IBM Blue Gene/P 系统(Hines 等人,2011 年)上展示了可扩展到 64,000 个内核,但随着新兴计算架构(如 GPU、众核架构)的出现,关键挑战是数值效率和可扩展性。 模拟器需要:
- (1) 公开细粒度并行性以利用大量硬件内核
- (2) 针对内存层次结构进行优化
- (3) 充分利用处理器功能,例如向量单元
要在给定的计算资源上模拟具有数十亿个神经元的模型,内存容量是另一个主要挑战。 为了应对这些挑战,NEURON 模拟器的计算算法被提取并优化到一个名为 CoreNEURON 的独立库中。
积分区间操作(在第 2 节中列出)消耗了大部分模拟时间。 CoreNEURON 的目标是考虑到不同的硬件架构,有效地实现这些操作。 本节介绍 CoreNEURON 与 NEURON 执行工作流的集成、主要数据结构更改以减少内存占用、NEURONCoreNEURON 之间的内存传输以及检查点恢复实现以促进长时间运行的模拟。
CoreNEURON 的主要设计目标之一是兼容现有的 NEURON 模型和用户工作流程。通过 CoreNEURON 库的集成,NEURON 模拟器支持图 1 中描述的三种不同的工作流程:
- (1)NEURON mode(NEURON模式)
- (2)CoreNEURON Online mode(CoreNEURON在线模式)
- (3)CoreNEURON Offline mode(CoreNEURON离线模式)
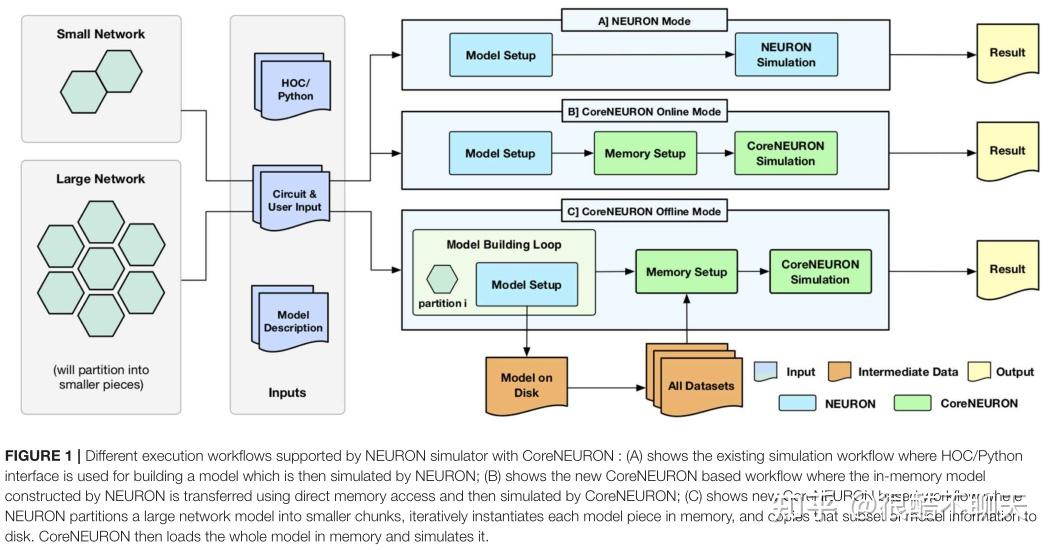
图一描述了带有 CoreNEURON 的 NEURON 模拟器支持的不同执行工作流程:
- (1)显示了现有的仿真工作流程,其中 HOC/Python 接口用于构建模型,然后由 NEURON 进行仿真。
- (2)展示了新的基于 CoreNEURON 的工作流程,其中由 NEURON 构建的内存模型使用直接内存访问传输,然后由 CoreNEURON 模拟。
- (3)展示了新的基于 CoreNEURON 的工作流程,其中 NEURON 将大型网络模型划分为较小的块,在内存中迭代地实例化每个模型块,并将模型信息的该子集复制到磁盘。 CoreNEURON 然后将整个模型加载到内存中并进行模拟。
NEURON模式:用 NMODL (Hines and Carnevale, 2000) 编写的模型描述用于构建可动态加载的共享库。 HOC/Python 脚本接口用于在内存中构建网络模型(模型设置阶段)。 然后使用第 2 节(仿真阶段)中描述的混合时钟事件驱动算法来仿真该内存模型。 用户可以完全控制模型结构,并可以使用脚本或图形用户界面(结果阶段)内省或记录所有事件、状态和模型参数。
CoreNEURON 在线模式:允许用户以最少的更改有效地运行他们的模型。 在模型设置阶段之后,内存中的表示被复制到 CoreNEURON 的内存空间中,然后在内存设置阶段重新组织内存以有效执行(参见第 4.2 节)。 仿真阶段在 CoreNEURON 中执行,并将脉冲结果写入磁盘。 请注意,在 NEURON 和 CoreNEURON 中使用了相同的 NMODL 模型描述。
CoreNEURON离线模式: 适用于由于内存容量限制而无法使用 NEURON 模拟的大型网络模型。 在这种模式下,模型设置阶段不是一次加载整个模型,而是构建适合可用内存的模型子集。 该子集被写入磁盘,子集使用的内存被释放,模型设置阶段构建另一个子集。 在 NEURON 写入所有子集后,CoreNEURON 从磁盘读取整个模型并开始仿真阶段。 由于 CoreNEURON 的单元和网络连接表示比 NEURON 的重量轻得多,因此可以使用 CoreNEURON 模拟比 NEURON 大 47 倍的模型(参见第 5 节)。
用户可以通过使用 (ParallelContext, 2019) 类的 nrncore_run 简单替换 psolve 函数调用,使现有模型适应 CoreNEURON 在线模式工作流程。
NEURON 被用作设计和试验的,具有不同解剖细节和膜复杂性的,神经模型的通用框架。在NEURON中,用户可以交互式地创建具有不同直径和长度的分支的细胞,插入离子通道,创建突触,并使用 GUI 可视化不同的属性。为了提供这种自省能力,NEURON 维护了大量复杂的数据结构。通常,一旦用户对模型的行为感到满意,他们就会在工作站或集群上运行更大/更长的模拟,而不再需要这些交互或详细的内省功能。
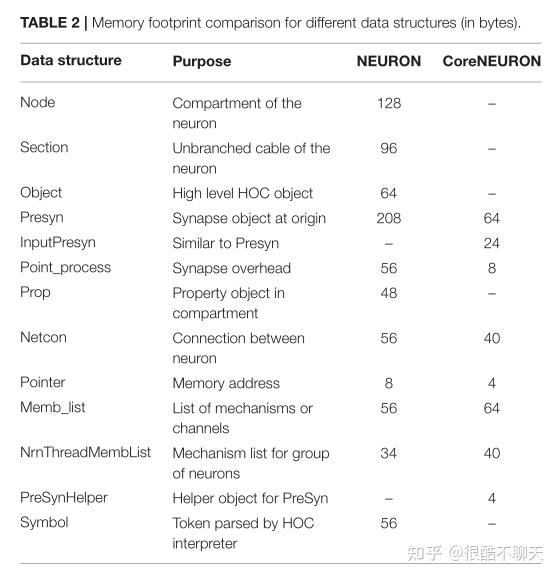
文章发现,在这种类型的批量执行中,可以通过用固定的数据结构数组替换它们,来显著减少来自大型复杂数据结构(具有大量相互指针)的内存开销,其中少数必要的指针被整数替换,这也是CoreNEURON在数据结构方面所做的贡献,或者说改进。例如网络连接对象(Netcon)和公共突触基类(Point_process),它们在 NEURON 中负责大量内存使用,而在 CoreNEURON 中分别从 56 字节减少到 40 字节和 56 字节到 8 字节。CoreNEURON 消除了 Python/HOC 解释器,因此不再需要像 Node、Section、Object 这样的数据结构。第 5 节讨论了针对不同网络模型的这些优化所带来的内存使用改进。表 2 列出了NEURON 和 CoreNEURON 的重要数据结构及其内存使用比较。
NEURON 用户可以通过使用 NMODL 的 POINTER 和 VERBATIM 结构来定义自己的数据结构并分配内存。
NEURON 的许多内部数据结构使用指针变量来管理各种动态属性、连接、事件队列等。由于模型是使用脚本接口增量构建的,因此在模型设置阶段会分配各种内存池。另外,由于 NEURON 和 CoreNEURON 之间的数据结构不同,序列化内存池成为 CoreNEURON 实现的主要内存管理挑战之一。通过序列化,指针变量需要增加元信息以允许 CoreNEURON 正确解码。该元信息指示指针语义。所有可能是目标指针的数据变量都被分组到一个连续的内存池中,并且指针变量被转换为内存池中的整数偏移量。当 NEURON 指针复制到 CoreNEURON 的内存空间时,与指针变量关联的语义类型用于计算相应的整数偏移量。
补充材料中列出了不同的语义类型及其用途(见paper的表 S1)
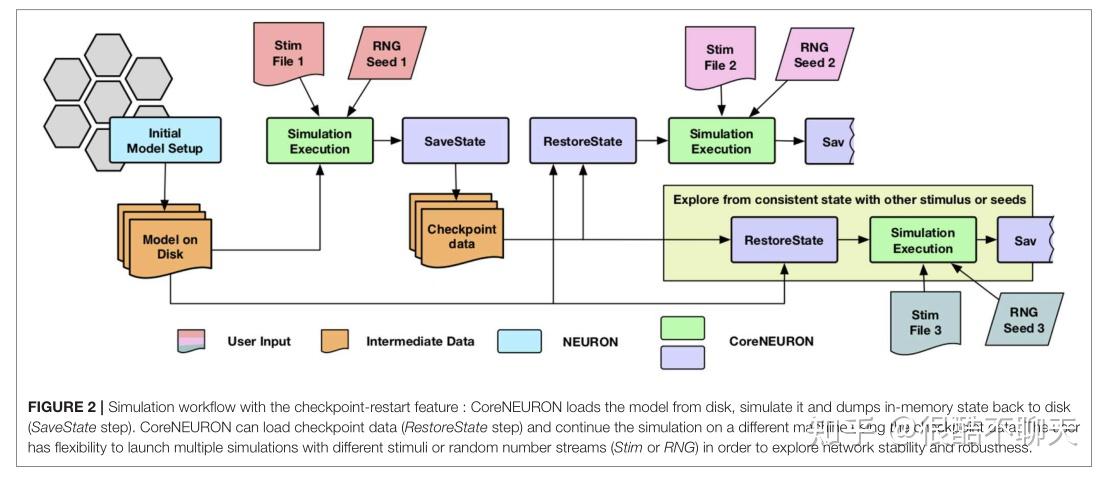
用于研究突触可塑性的网络模拟可以持续一周到一个月,而启用这种长生物时间尺度的模拟是 CoreNEURON 的重要用例之一。大多数集群和超级计算资源都有单个作业的最大挂钟时间限制(例如,最多 24 小时)。检查点重启是实现长时间运行模拟的常用技术,并已在 CoreNEURON 中实现。
由于检查点操作可以在任何时间以不同程度的细胞激发活动发生,因此除了保存模拟器的内存状态外,还必须考虑生成但未传递的突触事件。当一个单元触发时,它可能与具有不同传递延迟的其他单元有许多连接。在检查点操作期间,任何未传递的消息都会折叠回触发单元的原始事件中,以便可以保存单个事件。一旦网络模拟被检查点,用户可以灵活地启动具有不同刺激或随机数流的多个模拟,以探索网络的稳定性和鲁棒性。此类模拟的执行流程如图 2 所示。
在 CoreNEURON 中,用于脉冲传递的 MPI 通信和事件队列处理从 NEURON 继承并保留在 CPU 上。然而,当 GPU 正在使用时,一个时间步长内以特定突触类型为目的地的所有脉冲都被复制到 GPU 到特定类型的缓冲区,此后所有 NET_RECEIVE 块计算都在 GPU 上进行。 相反,阈值检测也发生在 GPU 上,并缓冲脉冲生成直到时间步长结束,此时缓冲区脉冲被复制到 CPU 以进行 MPI 传输并入队到优先级队列中。 此策略的一个例外是 ARTIFICIAL_CELL 实例仅通过其 NET_RECEIVE 块对传递事件的响应来计算和生成尖峰,仅存在于 CPU 上。
CoreNEURON 可以透明地处理所有脉冲网络模拟,包括使用固定时间步长方法的间隙连接耦合。用 NMODL 编写的模型描述需要利用现代 CPU 和 GPU 的向量单元。如果 MOD 文件包含用于临时存储的 GLOBAL 变量,则模型可以是非线程安全的,而这些变量通过在一个过程中分配一个值并在另一个过程中进行评估来使用。另外,此类变量需要从 GLOBAL 转换为 RANGE,这可以借助 NEURON 的 smkthreadsafe 工具来实现,或者用户可以手动对此类 MOD 文件进行细微更改。
NMODL 中添加了 COREPOINTER 和 CONDUCTANCE 等新关键字,以分别促进序列化和提高性能优化。这些关键字也被反向移植到 NEURON,以便模型与 NEURON 或 CoreNEURON 执行保持兼容。为了在 GPU 等平台上实现随机数的可扩展性和可移植性,CoreNEURON 支持 Random123 伪随机生成器 (Salmon et al., 2011)。
为了提高CoreNEURON在不同架构上的性能,在多线程、内存布局、向量化、代码生成等方面实施了不同的优化方案。 本节介绍了这些优化。
NEURON 和 CoreNEURON 都使用消息传递接口(MPI)来实现分布式内存并行。尽管 NEURON 支持基于 Pthread 的多线程,但由于更好的缩放行为,用户通常使用纯 MPI 执行。但是,在大规模执行时,由于 MPI 通信和内部 MPI 缓冲区的内存开销,纯 MPI 执行会影响可扩展性。
为了解决这种可扩展性和并行性挑战,CoreNEURON 依赖于三个不同级别的并行性:
- 首先,在最高级别,一组具有等效计算成本的神经元被组合在一起并分配给计算节点上的每个 MPI 等级。
- 其次,在一个节点内,一个单独的神经元组被分配给一个在核心上执行的 OpenMP (Dagum and Menon, 1998) 线程。该线程为整个模拟模拟给定的神经元组,确保数据局部性。
- 最后,核心的向量单元用于并行执行多组通道。对于 MPI 和 OpenMP ,模拟可能受益于每个计算节点更少的 MPI 进程(每个节点一个进程)。
基于目标架构,用户可以选择多个 MPI rank 和每个 rank 对应的 OpenMP 线程,以减少通信开销。
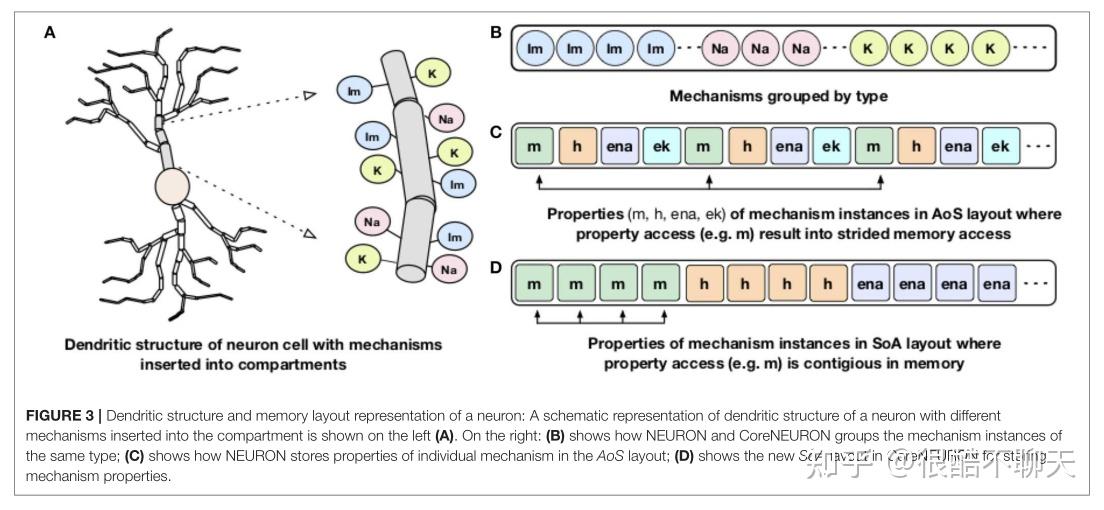
处理器内存带宽是稀缺资源之一,通常是提高包括 NEURON 在内的许多应用程序性能的主要障碍。而通道和突触的计算内核带宽有限,通常可以达到接近峰值的内存带宽。图3中较为详细地描述了神经元和树突结构及其布局:
神经元的树突结构分为小隔室,不同的膜通道或机制插入不同的隔室(图 3A)。另外,对于内存局部性,NEURON 和 CoreNEURON 都按通道类型对通道进行分组(图3B)。但是,神经元在结构阵列 (AoS) 内存布局(图 3C)中组织了各个机制的属性(如 m、h、ena)。当访问特定属性时,例如,m,会导致内存带宽利用率低下的跨步内存访问,从而导致性能不佳。
为了解决这个问题,CoreNEURON 将通道属性组织到数组结构 (SoA) 内存布局中(图 3D)。这允许对所有通道和突触计算进行有效的矢量化和有效的内存带宽利用。对于代码矢量化,CoreNEURON 依赖于编译器的自动矢量化功能。为了帮助编译器进行自动矢量化,使用了#pragma ivdepare 之类的提示。
自 1989 年发布第 2 版以来,NEURON 已通过模型描述语言 NMODL 支持代码生成。 NEURON 的代码生成程序已被修改为一个名为 MOD2C的独立工具。
https://github.com/BlueBrain/mod2cCoreNEURON 使用此工具支持所有用 NMODL 编写的 NEURON 模型。图 4 显示了 MOD2C 的高级工作流程。源到源翻译器的第一步是词法分析,其中检测 NMODL 代码中的词法模式并生成标记。语法分析步骤使用这些标记并确定该系列标记是否适用于该语言。语义分析步骤确保句法有效的句子作为模型描述的一部分是否有意义。代码生成是使用编译器提示创建 C++ 文件的步骤,用于自动矢量化(例如#pragma ivdep)和使用 OpenACC 编程模型的 GPU 并行化。 MOD2C 还负责 AoSandSoA 内存布局的代码生成。 MOD2C 使用开源 flex 和 bison 工具进行此实现。
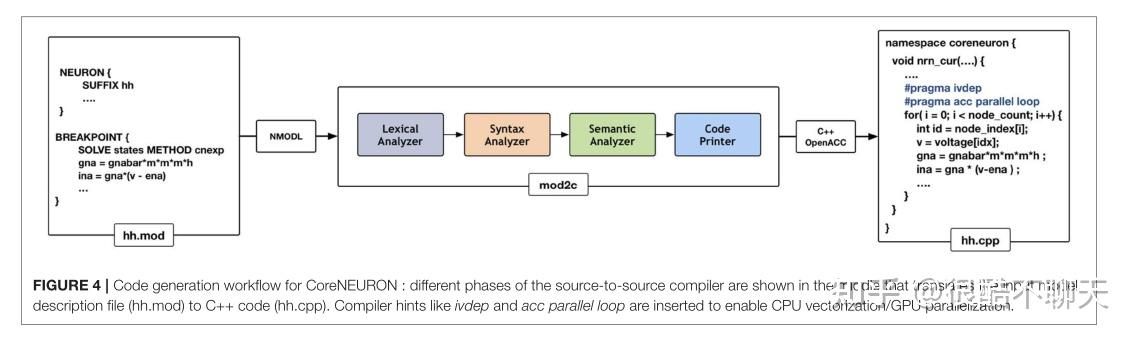
关于 NMODL 代码生成管道的更多信息可以在 Blundell 等人的工作中找到:https://www.frontiersin.org/articles/10.3389/fninf.2018.00068/full
Blundell, I., Brette, R., Cleland, T. A., Close, T. G., Coca, D., Davison, A. P., et al. (2018). Code generation in computational neuroscience: a review of tools and techniques.Front. Neuroinform.12:68. doi: 10.3389/fninf.2018.00068
在 CoreNEURON 项目之前,人们付出了大量努力,使用 CUDA 编程模型将 NEURON 移植到 GPU 架构。此实现的两个主要组件之一是 NMODL 源到源编译器的扩展以发出 CUDA 代码。另一个主要组件管理从 NEURON 的线程高效的 AoS 内存布局,到 GPU 内存效率更高的 SoA 布局的内部内存转换。
为了生成 CUDA 代码,有一个单独版本的 NMODL source-to-source 编译器。 NEURON 维护复杂的段、段数据结构以供交互使用。 CPU 和 GPU 之间这些非 POD 类型(Plain Old Data)数据结构的内存管理非常复杂,因为内存分配不连续。这个实验性的 NEURON 版本对于蜂窝模拟的矩阵设置和通道状态集成非常有效,但没有达到网络模拟能力。该项目失败的原因有以下几点:
- (1)维护两个完全独立的代码库的软件管理困难
- (2)难以理解从 AoS 到 SoA 的内存布局转换所涉及的数据结构变化
- (3)在缺乏指针语义信息的情况下管理指针更新困难
而CoreNEURON 的开发提出了一个观点,不仅可以缓解 GPU 的这些问题,而且有机会发展到在未来的架构上工作。正如第 4.2 节所述,CoreNEURON 数据结构和内存布局已针对高效内存访问进行了优化。 MOD2C 支持使用 OpenACC 编程模型生成代码,该模型有助于针对不同的加速器平台。用户需要使用支持 OpenACC 的编译器编译 CoreNEURON 库。图 5 显示了启用 GPU 的执行工作流程,其中描述了在 CPU 和 GPU 上运行的 CoreNEURON 模拟器的不同阶段。
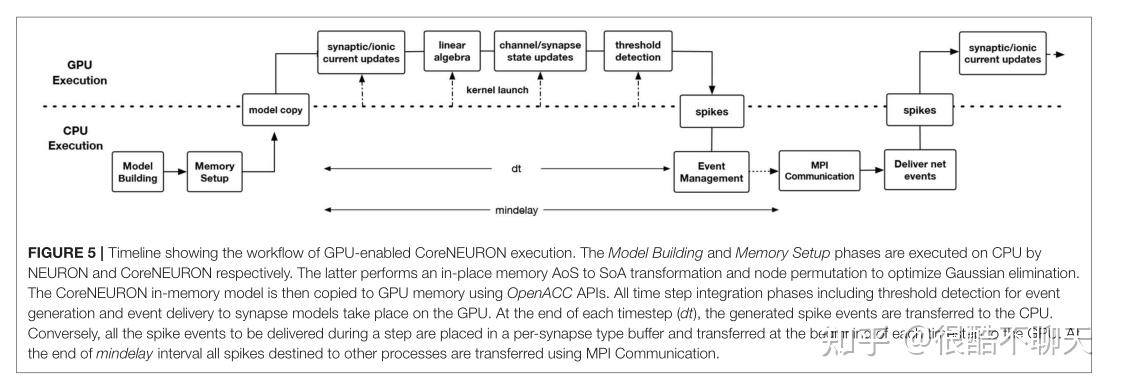
关于该创新性开发的具体细节见paper 第8页4.4部分。
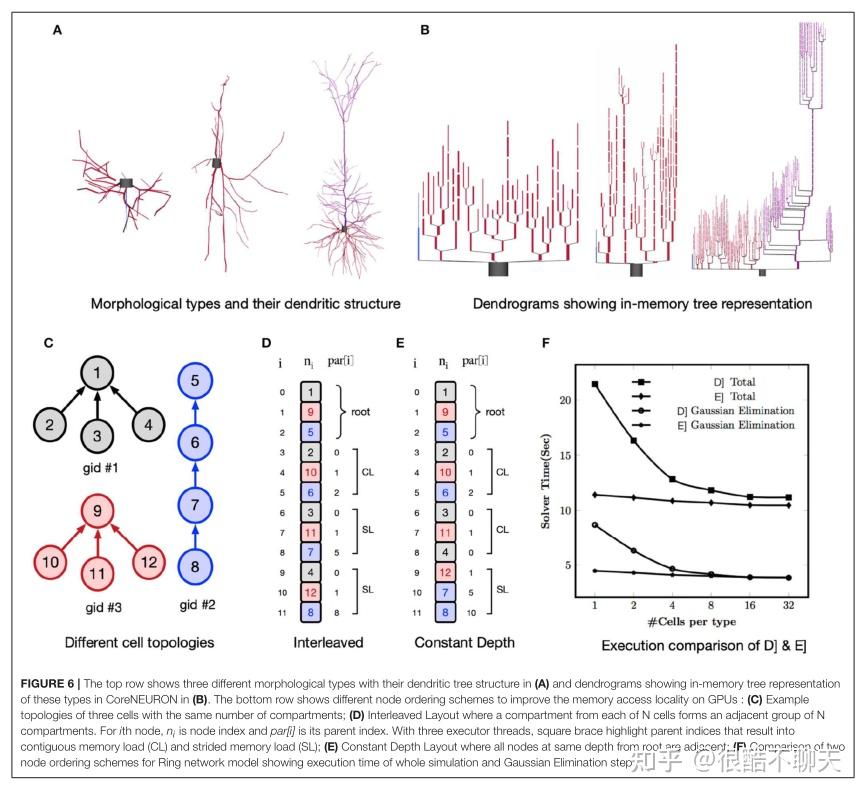
另外,在本小节,作者详细说明了神经元的的模型与拓扑结构。如下图6所示,图片顶行显示了三种不同的形态学类型,在(A)中显示了它们的树突树结构,在(B)中显示了这些类型在 CoreNEURON 中的内存中树表示的树状图。 底行显示了不同的节点排序方案,以改善 GPU 上的内存访问局部性:(C) 具有相同隔间数量的三个单元的示例拓扑;(D) 交错布局,其中来自 N 个单元中的每个隔间形成相邻的一组 N个隔间。 第四个节点,niis 节点索引,par[i]是它的父索引。 使用三个执行器线程,方括号突出显示导致连续内存负载 (CL) 和跨步内存负载 (SL) 的父索引;(E) 恒定深度布局,其中距根相同深度的所有节点都相邻;(F) 两个的比较 环形网络模型的节点排序方案显示了整个仿真和高斯消除步骤的执行时间。
并非所有网络模型都是计算密集型的,也不是从 CoreNEURON 优化中同等受益。 为了评估上一节中讨论的优化的性能改进,我们在不同的计算架构上运行了表 1 中列出的几个已发布的网络模型。 本节介绍基准测试平台并比较 NEURON 和 CoreNEURON 之间的性能。
带有硬件细节、编译器工具链和网络结构的基准测试系统总结在表 3 中。
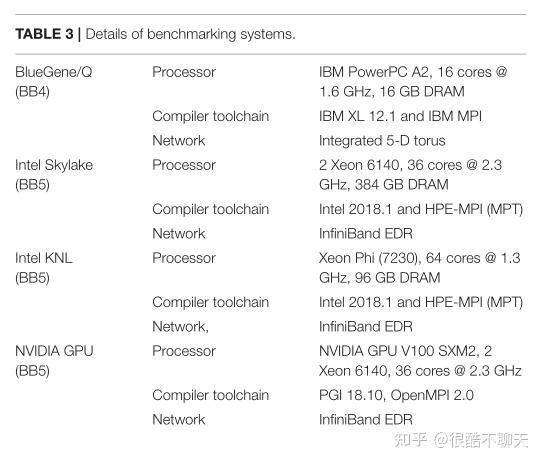
其中,Blue Brain IV (BB4) 和 Blue Brain V (BB5) 系统分别基于 IBM BlueGene/Q 和 HPE SGI 8600 平台,托管在瑞士位于瑞士卢加诺的国家计算中心 (CSCS)。
BB4 系统有 4,096 个节点,包括 65,536 个 PowerPC A2 内核。 BB5 系统具有三个不同的计算节点:
- 具有低时钟速率但高带宽 MCDRAM 的 Intel KNL
- 具有高时钟速率的 Intel Skylakes
- NVIDIA Volta GPU
两个系统都使用供应商提供的编译器和 MPI 库。 BB4 系统用于强大的扩展基准测试(参见图 8),因为与 BB5 系统相比,它具有更多的内核数。通过为每个内核固定一个 MPI 等级,所有基准测试都是在纯 MPI 模式下执行的。在模型构建阶段,NEURON 将模型分成相等的块,其中 MPI 排名的总数。 CoreNEURON 继续执行与 NEURON 相同数量的 MPI 等级。对于 GPU 执行,我们对每个 GPU 节点使用一个 MPI 等级。
另外,我们比较了表 1 中列出的不同网络模型的内存占用。 内存减少因子取决于各种模型属性(例如,隔室、部分、突触等的数量),但使用 CoreNEURON 可以预期减少 4-7 倍。 请注意,在内存设置阶段,CoreNEURON 在线模式将需要 1 7 到 1 4 倍的内存。 但是一旦模型转移到 CoreNEURON 进行仿真,NEURON 就可以释放分配的内存。
图 7 的左侧图示显示了 CoreNEURON 仿真与 NEURON 仿真相比内存使用量的减少。右侧图示显示了与 NEURON 相比,CoreNEURON 的不同模型在单个节点上实现的加速。 请注意,Cortex 和 Hippocampus 模型在内存容量要求方面非常大。 对于单节点性能分析,我们使用了这两个模型的较小子集。
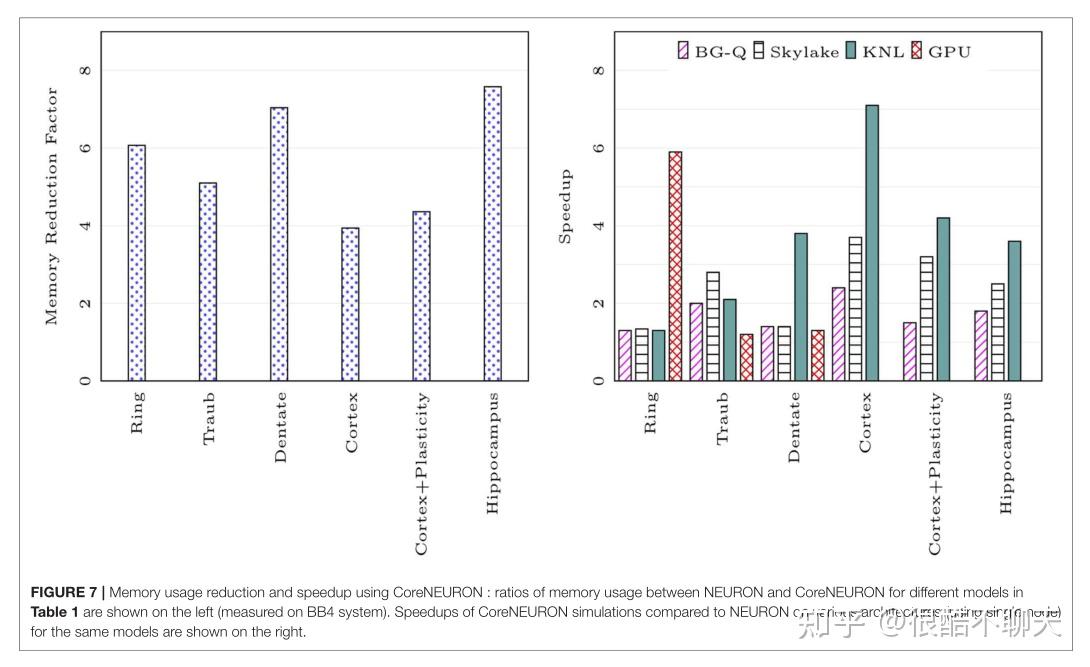
另外,当大部分计算时间花在通道和突触计算上时,第 4.2 节中描述的内存布局和代码矢量化优化显示出最大的改进。 我们知道,Cortex、Cortex+Plasticity 和 Hippocampus 模型的细胞具有 200 到 800 个隔室和 20 种不同的通道类型。这使得这些模型计算密集,并让它们从 CoreNEURON 中获益最多。而环形网络模型仅从被动树突和主动体进行计算。
在 CoreNEURON 的情况下,NMODL 生成的代码由编译器自动矢量化,并具有 SoA 内存布局,以提供统一、连续的内存访问。 NEURON 使用 AoS 内存布局,这导致了跨步内存访问。同时,由于 KNL 内核的时钟频率较低,与其他架构相比,非矢量化代码和跨步内存访问对性能的影响很大。
英特尔 KNL 具有 512 位 SIMD 矢量和高带宽内存 (MCDRAM)。人们需要有效地利用这些硬件功能来实现最佳性能。
因此,与 NEURON 相比,CoreNEURON 在 KNL 上提供了更好的性能。请注意,与 Cortex 模型 (3-7x) 相比,Cortex+Plasticity 和 Hippocampus 模型的改进相对较少 (2-4x)。这是因为某些通道和突触描述明确要求当前编译器无法有效矢量化的集成方法。文章也提到,团队正在考虑为这些方法生成替代代码。在 BlueGene/Q 平台上,大多数模型的加速速度限制为 2 倍。这是因为 IBM XL 编译器无法矢量化大多数通道和突触内核。在这个平台上观察到的性能改进是由于来自 4.2 节中讨论的 SoAlayout 的更高效的内存访问。
CoreNEURON除了在性能上的优势之外,作者团队最近的工作中还为其添加了 GPU 支持。 该Benchmarks测试中使用的两个模型: Cortex+Plasticity 和 Hippocampus ,使用尚未适用于 GPU 的基于 HOC 的传统刺激实现。 环形网络模型具有大量相同的单元,适合在 GPU 上进行 SIMD 计算,因此与其他架构相比显示出显着的性能提升。 Traub 模型有少量单元暴露有限的并行性,而 Denate 模型有间隙连接,需要在每个时间步复制 CPU 和 GPU 之间的电压。 这限制了 GPU 的性能提升。
而相比于以上情况,模型内存占用的减少直接转化为大规模模型用户的好处。例如,虽然 Cortex + Plasticity 和海马模型大小的模型在使用 NEURON 时需要内存,这需要 IBM BlueGene/Q 系统上的至少 2,048 个节点,可以 现在运行在同一系统上,当使用 CoreNEURON 离线模式时,Cortex+Plasticity 和 Hippocampus 模型分别只需要 128 或 256 个节点。 这是一个显着的可用性改进,并直接转化为更好地利用用户的计算分配。
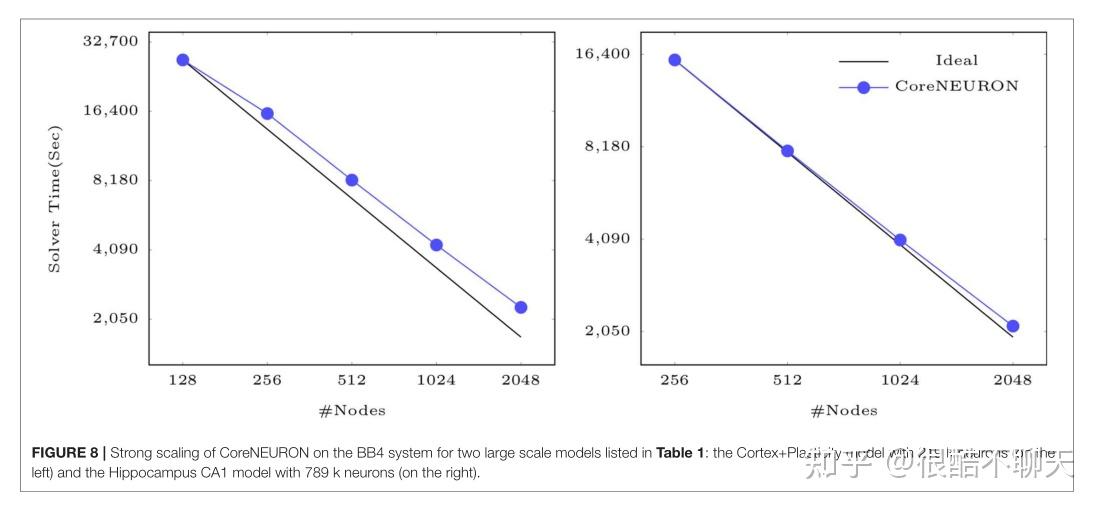
最后,图 8 显示 CoreNEURON 为大型模型保持良好的强缩放特性,如:在 IBM BlueGene/Q 系统上模拟一秒生物时间的 Cortex+Plasticity ,和海马模型示例。两种模型都显示出高达 2,048 个节点的出色强扩展行为。 由于形态电神经元类型的大小范围很大,每个 MPI 过程至少需要 7-10 个细胞才能实现良好的负载平衡。 使用 32,000 个 MPI 进程(每个节点 16 个等级)和大约 219,000 个 Cortex+Plasticity 单元,负载平衡不如海马模型的大约 789,000 个单元。 因此,与海马模型相比,Cortex+Plasticity 模型表现出较差的缩放行为。
由于上述的两个模型示例是计算密集型的,并且一小部分执行时间花在脉冲通信上,因此缩放行为取决于给定数量的单元在可用的等级数上分布的程度,以产生良好的负载平衡。
现代计算架构可以显着提高应用程序性能,而大脑的研究迫切需要拥抱这种能力和趋势。因此,多年来广泛使用的支持多种模型的 NEURON 模拟器已经成功地适应了大规模并行架构,但其主要设计目标是允许模型的灵活定义和交互内省。它既不是为了终极内存效率,也不是为了最大性能而设计的。然而,模型越大越详细,模拟这些模型的资源需求就越大。最终,未优化模拟器所需的系统成本应与重新设计模拟器以更有效地利用资源的努力进行权衡。在 Blue Brain 项目的背景下,我们决定为使 NEURON 模拟器更高效地处理大型模型做出贡献,从而有效地减少资源需求、缩短解决方案的时间,或者只是能够在给定的模型上运行更大的模型资源。
由于paper的discussion比较重要,所以这里就较为详细地翻译并做以解释。
由于神经科学界已经开发并与 NEURON 共享了数以千计的模型,兼容性和可重复性一直是主要的设计目标之一。 为了保持最大的兼容性,我们选择了将 NEURON 的计算相关部分提取到一个名为 CoreNEURON 的库中并对其进行调整以利用现代计算架构的计算特性的路径。 这是一条不同的道路,例如 Arbor (Akar et al., 2019) 从头开始开发。
虽然这样一个全新的开始从一开始就为未来的架构设计有其好处,但我们可以证明,我们立即采取的转换方法以最少的修改与大量现有的 NEURON 模型兼容。 目前,CoreNEURON 不处理非线程安全模型,如果使用像 POINTER 这样的结构,则需要修改 NMODL。 我们正在努力透明地处理此类模型。
许多与详细大脑模型相关的建模工作流程需要灵活地快速检查和更改模型。 通过从 NEURON 模拟器环境中提取计算引擎并提供它如何与 NEURON 模拟器交互的不同方法,可以保持 NEURON 构建模型的灵活性,并且可以更轻松地将优化应用于计算引擎以进行昂贵的模拟 阶段。
CoreNEURON 的离线执行模式提供了构建和模拟 NEURON 无法模拟的大型网络模型的灵活性。 由于使用了 MPI 以及 OpenMP 和 OpenACC 编程模型,以实现跨不同架构(如多核、众核 CPU 和 GPU)的可移植性。
与 NEURON 相比,数据结构的变化允许 CoreNEURON 使用更少的内存。 SoA 内存布局和代码矢量化允许 CoreNEURON 有效地模拟模型。 我们在不同架构上对五种不同的网络模型进行了基准测试,结果显示内存使用量减少了 4-7 倍,执行时间缩短了 2-7 倍。
我们讨论了 NEURON 和 CoreNEURON 中最重要的变化和优化的实现。虽然 CoreNEURON 可以在 NEURON 中透明地使用,但用户目前无法在集成期间访问或修改模型属性。
关于双向数据复制例程激活的工作正在进行中,由 normalNEURON 变量名评估和赋值语法的粒度范围从整个模型到特定的命名数组,再到单个变量。
在数值方面,CoreNEURON 现在支持使用固定时间步长方法而不是可变时间步长积分方法 (CVODE) 的网络模拟(Cohen 和 Hindmarsh,1996 年)。后者很少用于网络模拟,因为响应突触事件的状态或参数不连续需要可变步长积分器的连续重新初始化。
关于如何提高可变时间步长方案在网络仿真中的适用性的研究正在进行中,可以考虑在稍后阶段纳入。目前,多个 MPI 等级到 GPU 的映射不是最佳的,这将在未来的版本中解决。
最后,NMODL 源到源转换器将得到改进,以便为需要推导隐式积分方法的刚性、耦合、非线性门控状态复合体生成高效代码,并为 GPU 生成最佳代码。
CoreNEURON 和代码生成程序 MOD2C 是开源的, GitHub Link:http://github.com/BlueBrain/mod2c
——2021.11.5(完)
【2021.11.2-2021.11.5 记】




